Automated Binary Analysis: A Survey
Automated Binary Analysis: A Survey
Liu, Zian, Chao Chen, Ahmed Ejaz, Dongxi Liu, and Jun Zhang. "Automated Binary Analysis: A Survey." In International Conference on Algorithms and Architectures for Parallel Processing, pp. 392-411. Cham: Springer Nature Switzerland, 2022.
作者单位:澳大利亚斯威本科技大学、 澳大利亚联邦科学与工业研究组织(CSIRO)、澳大利亚皇家墨尔本理工大学
1. 介绍
二进制分析的场景:
- 分析恶意软件
- 分析已编译的软件
- 分析闭源操作系统(如Windows、iOS等)
本文主要关注流行平台上的二进制文件,包括
- 常见个人计算机平台(即Windows和Linux)
- Android
- iOS
目前对二进制分析的研究可分为两类:
- 数据驱动的二进制分析:通过训练自动学习模型,可用于预测、签名推断等
- 基于软件工程的二进制分析:需要使用各种传统的静态(离线)、动态(在线)、混合程序分析技术和其他自动化程序分析方法来解决特定的研究问题。
Harry:
二进制代码自动利用技术是指利用计算机程序或系统中的二进制代码进行攻击的自动化过程。这些技术通常涉及使用计算机程序来发现、利用和利用程序或系统中的漏洞,而无需直接的人工干预。以下是一些常见的二进制代码自动利用技术:
- Fuzzing(模糊测试): 模糊测试是通过向程序输入不同的、通常是随机生成的数据(即“模糊”数据)来检测软件漏洞的一种技术。自动化的模糊测试工具可以在短时间内生成大量的测试用例,以检测程序的异常行为和潜在的漏洞。
- Exploit Generation(利用代码生成): 利用代码生成工具能够自动分析程序中的漏洞,并生成用于利用这些漏洞的代码。这些工具通常使用静态和动态分析技术,尝试自动生成恶意代码,以实现对系统的攻击。
- ROP(Return-Oriented Programming)攻击: ROP 攻击利用程序中现有的代码段(通常是函数调用)来构建恶意的代码执行路径,而无需注入新的代码。自动化的ROP链生成工具能够自动生成这些攻击链。
- Semantic-Based Exploitation: 这种技术使用语义分析方法来理解程序中的漏洞,并自动生成用于利用这些漏洞的代码。这种方法侧重于理解程序行为的语义,而不仅仅是静态或动态的分析。
- Concolic Testing: 这是一种结合了具体执行和符号执行的技术,通过在程序执行的基础上进行符号分析,以自动生成用于漏洞利用的输入。
- Automatic Patching: 一些工具试图通过自动生成补丁来修复程序中的漏洞,从而减轻潜在的攻击。这是一种自动化的防御方法,但并非所有漏洞都可以轻松地通过自动补丁来修复。
本文对一系列主题进行了调查,包括恶意软件分类和检测、程序恶意性检测、二进制代码相似性检测、逆向工程、二进制代码利用、二进制代码重写、二进制代码漏洞检测等。
2. 数据驱动的二进制分析
数据驱动的二进制分析包括传统的基于机器学习的算法(例如k-最近邻算法(k-NN)、支持向量机(SVM)、随机森林(RF)等)和深度学习算法(例如循环神经网络(RNN)、深度神经网络(DNN)及其变种)。
本文基于平台、提取的特征及学习模型对所有的数据驱动型研究进行了分类,如下:
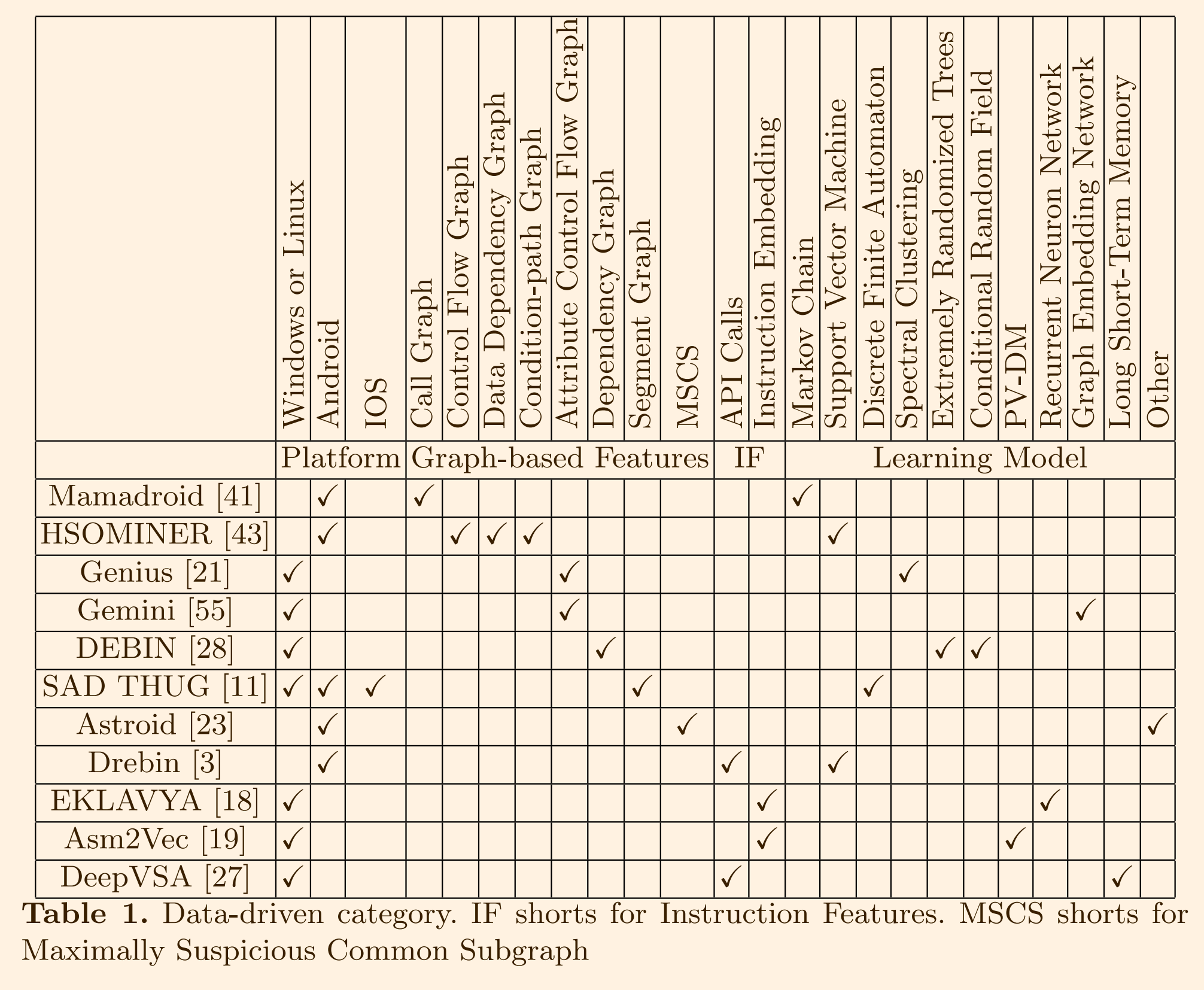
2.1 二进制表示的特征工程
基于图的特征
- Mamadroid(2019):首先提取了应用程序 API 调用的调用图。然后将 API 调用的序列分为两个不同的级别,即包名(例如 java.lang)和家族名(例如 java、android、google)。通过使用马尔可夫链来捕捉每两个调用之间的过渡的频率。
Harry:
马尔可夫链是一种数学模型,描述了在给定当前状态下系统可能转移到的下一个状态的概率。在这里,将调用序列视为状态的序列,而两个相邻的调用之间的转换被视为状态之间的转移。
使用马尔可夫链对程序的 API 调用图进行建模通常包括以下步骤:
- 定义状态: 在 API 调用图中,每个节点(API 调用)可以被视为一个状态。定义状态集合,即图中所有可能的 API 调用。
- 确定状态转移概率: 对于每对相邻的 API 调用,计算状态之间的转移概率。这反映了在给定当前 API 调用的情况下,下一个调用是什么的可能性。这里可以使用一些统计方法或机器学习技术来估计这些概率。
- 构建状态转移矩阵: 将状态之间的转移概率整理成状态转移矩阵。矩阵的每个元素(i, j)表示从状态 i 转移到状态 j 的概率。
- 定义初始状态分布: 定义初始状态的分布,即在分析开始时每个 API 调用作为起始状态的概率。这可以是均匀分布,也可以基于实际数据的先验知识。
- 进行模型训练或推断: 根据实际的 API 调用序列数据,可以使用马尔可夫链模型进行训练或推断。这有助于优化状态转移概率,并更好地适应实际应用程序的行为。
- 模型评估: 对构建的马尔可夫链模型进行评估,通常涉及使用一些性能指标来检查模型对观察数据的拟合程度。这可以包括对模型的预测准确性、状态转移概率的准确性等进行评估。
HSOMINER(2017):将代码转换为中间语言(IR),构建全局控制流图(CFG)和反向数据依赖图(DDG)。HSOMINER 定位包含敏感活动的基本块,并使用 CFG 和 DDG 生成条件路径图(CPG)。然后,HSOMINER 提取以下特征:1)导致调用隐藏活动的触发条件,2)具有和不具有隐藏活动的路径之间的行为差异,3)条件路径关系,例如某些操作或变量与条件内其他变量之间的数据依赖。
Genius(2016):基于属性控制流图(ACFG)提取特征。这些特征包括统计特征和结构特征。统计特征包括字符串常量、数字常量、传输指令数量、调用数量、指令数量和算术指令数量。结构特征包括后代数量和介数中心性,该中心性测量图中节点的中心位置。Gemini也使用了Genius中提出的与ACFG相关的特征。区别在于ACFG特征的处理和学习方法。
DEBIN(2018):将汇编代码转换为一个名为 BAP-IR 的中间表示,并构建了一个依赖图。然后,从图中提取各种程序元素,包括函数、寄存器变量、内存偏移变量、类型、标志、指令、常量、位置和一元操作,作为特征。
Harry:
BAP-IR(Binary Analysis Platform Intermediate Representation)是一种中间表示,用于表示汇编或机器码的程序。它是由Binary Analysis Platform(BAP)提供的,旨在支持对二进制代码进行静态和动态分析。
BAP-IR具有以下特征:
- 模块化结构: BAP-IR通过将二进制代码划分为多个模块,每个模块表示程序的一个组成部分,从而实现了模块化的表示。
- 高级抽象: BAP-IR采用了高级的抽象层次,这使得分析人员能够更容易地理解和处理二进制代码,而无需深入研究具体的机器指令。
- 指令和数据表示: BAP-IR能够表示二进制代码中的指令和数据。这为分析人员提供了关于程序行为和数据流的信息。
- 控制流和数据流: BAP-IR捕捉了程序的控制流和数据流信息,帮助分析人员理解程序的执行路径和数据传递。
SAD THUG(2018):将输入二进制文件分解为段序列,并将其抽象为一个有向图。然后,捕捉从一个段到另一个段的可能转换作为一种良性特征。他们将这些转换中的段顺序和长度视为特征。由于恶意和良性文件的不平衡,他们只对从良性图像中提取的特征进行训练。
Astroid(2017):为每个恶意软件家族中的所有样本提取最大可疑公共子图(MSCS)。他们捕捉了 MSCS 的特征,如节点类型、节点元数据、节点之间的控制流等。
指令特征与嵌入
- Drebin(2014);提取了反汇编代码的特征,例如受限制的 API 调用的存在、已使用的权限、可疑的 API 调用和网络 IP 地址。其他一些工作通过使用自然语言处理(NLP)方法和模型来学习指令的语义。
Harry:
⭕ 貌似一部分跟指令无关
- EKLAVYA(2017): 使用了 skip-gram 负采样方法和词嵌入技术来学习每个指令的嵌入。他们还在嵌入中考虑了每个指令的上下文信息。
Harry:
使用了skip-gram负采样方法和词嵌入技术来学习每个指令的嵌入,通常涉及以下步骤:
- 数据准备: 准备包含汇编指令序列的数据集。每个指令可以被看作是模型学习的一个“词”。
- Tokenization: 将每个汇编指令序列进行标记化,将其拆分为单个指令。每个指令将成为skip-gram模型的一个“词汇”。
- Skip-gram模型构建: 使用skip-gram模型的实现(例如Word2Vec库中的skip-gram模型)构建一个模型。在skip-gram模型中,模型尝试根据给定的上下文来预测目标词汇(或指令),从而学习到词汇之间的语义关系。
- Negative Sampling: 为了降低训练的计算成本,skip-gram模型通常使用负采样方法。对于每个训练样本,会选择一些负样本(未出现在上下文中的词汇)来进行训练。这有助于提高训练效率。
- 词嵌入训练: 使用准备好的数据集对skip-gram模型进行训练。模型将学习将每个指令嵌入到一个连续的向量空间中,以便在这个向量空间中保留指令之间的语义关系。
- 获取嵌入表示: 训练完成后,可以通过查询模型以获取每个指令的嵌入表示。这些嵌入向量将包含指令的语义信息。
skip-gram模型通过学习从上下文到目标的映射,以及使用负采样方法,能够在训练过程中有效地捕捉指令之间的语义关系。这使得skip-gram模型在学习指令嵌入时能够更好地理解指令在语义空间中的位置。
- Asm2Vec (2019): 使用 PV-DM 模型通过无监督学习从汇编代码中学习每个指令的嵌入表示。
Harry:
PV-DM(Paragraph Vector-Distributed Memory)是一种用于学习嵌入表示的模型,通常用于处理文本数据。在汇编代码中,可以将每个指令视为文本数据的一个“段落”或“句子”,然后使用PV-DM模型学习每个指令的嵌入表示。以下是使用PV-DM模型进行无监督学习的一般步骤:
- 数据准备: 准备包含汇编指令序列的数据集。每个指令序列可以被看作是一个“段落”。
- Tokenization: 将每个汇编指令序列进行标记化,将其拆分为单个指令。每个指令将成为PV-DM模型的一个“词汇”。
- PV-DM模型构建: 使用PV-DM模型的实现(例如,gensim库中的Doc2Vec模型)构建一个模型。在PV-DM模型中,通常有两个部分:Distributed Memory (DM) 和 Distributed Bag of Words (DBOW)。在DM模型中,每个“段落”(指令序列)都有一个唯一的标识符,而在DBOW模型中,整个“段落”被视为一个单一的词。
- 无监督训练: 使用准备好的数据集对PV-DM模型进行无监督训练。模型将每个指令嵌入到一个连续的向量空间中,以捕捉指令之间的语义关系。
- 获取嵌入表示: 训练完成后,可以通过查询模型以获取每个指令的嵌入表示。这些嵌入向量将包含指令的语义信息。
在整个过程中,PV-DM模型通过无监督学习从数据中学习嵌入表示,而不需要预定义的标签。这使得模型能够自动捕捉指令之间的语义关系,为进一步的分析和任务提供了有用的信息。
- DeepVSA (2019): 使用长短时记忆(LSTM)来学习每个指令的一热编码嵌入。
Harry:
使用长短时记忆网络(LSTM)来学习每个指令的一热编码嵌入涉及以下步骤:
- 数据准备: 准备包含指令序列的训练数据。每个指令序列都应该被表示为一个由单词(指令)组成的序列。
- one-hot编码: 将每个指令表示为一个one-hot编码向量。one-hot编码是一种二进制编码形式,其中只有一个元素为1,其余为0。对于每个指令,编码的长度应该等于词汇表的大小,其中每个位置代表一个可能的指令。
- 建立LSTM模型: 创建一个LSTM模型,该模型能够接受one-hot编码序列作为输入并学习嵌入表示。LSTM是一种递归神经网络,能够捕捉输入序列中的长期依赖关系。
- 嵌入层: 在LSTM模型中添加一个嵌入层。嵌入层用于将one-hot编码向量映射到一个低维连续向量空间中,这就是所谓的嵌入。嵌入层的权重将在训练过程中学习,以便最好地捕捉输入指令的语义信息。
- 训练模型: 使用带有目标指令的指令序列训练LSTM模型。在训练期间,LSTM将学习如何将one-hot编码序列映射到嵌入空间中,并捕捉指令之间的语义关系。
- 获取嵌入表示: 在模型训练完成后,可以使用学到的嵌入层来获取每个指令的嵌入表示。给定一个新的指令,通过模型的嵌入层传递one-hot编码,即可获得该指令的嵌入向量。
- 应用嵌入表示: 学到的嵌入表示可以应用于各种任务,如相似性比较、聚类或其他与指令语义相关的任务。
2.2 二进制分析模型训练
根据不同任务(如恶意软件预测、漏洞检测、相似性分析等)选择不同模型。
MAMADroid: 基于 API 调用序列构建马尔可夫链,学习每两个调用之间过渡的频率。API 调用序列的频率指示了应用的恶意程度。
Drebin(2014): 将所有特征转换为one-hot向量,并使用支持 向量机(SVM) 来学习基于这些特征的恶意软件分类模型。
HSOMINER: 利用触发条件及其对应路径相关的特征,以及指示实例是否为 HSO 的标签,来训练一个 SVM 分类模型。
SAD THUG: 使用所有训练样本的段图来为训练算法提供输入,以构建离散有限自动机,该自动机捕捉了普通镜像文件中一个段到另一个段的可能过渡。
Feng, Q等(2016): 使用提取的 ACFG 并计算原始特征相似性,基于谱聚类对特征进行聚类,以生成代表镜像文件漏洞的codebook。
DEBIN: 使用 极端随机树(ET) 模型和其他一些规则来预测哪些元素是已知的(不应该被预测),哪些是未知的(因此应该被预测)。使用 条件随机场(CRF) 模型表示条件概率分布,并执行最大后验(MAP)推断,以确定未知元素的最可能分配。
Asm2vec: 使用 PV-DM 模型从汇编代码中学习向量表示,包括存储库函数向量、每个标记的词汇语义向量及其预测向量。学到的汇编代码向量可用于二进制代码相似性检测。
EKLAVYA: 使用 循环神经网络(RNN) 模型:基于调用者指令计算每个函数的参数数量,基于被调用者指令计算每个函数的参数数量,基于调用者指令恢复参数类型,基于被调用者指令恢复参数类型。训练好的模型可以用于恢复反汇编的二进制代码函数类型。
Gemini: 使用基本的 Structure2vec 方法递归地聚合图的拓扑结构和逐顶点特征。使用 孪生架构学习网络 中的参数,通过将地面真实相似 ACFG 对作为输入,优化目标函数。训练好的模型可用于预测两个给定的二进制函数是否相似。
DEEPVSA: 为每个指令使用双向 LSTM 模型生成单独的指令嵌入。在这一步中使用前向和后向网络。它还使用一个序列到序列模型,以指令嵌入为输入,预测标签,如每个指令的内存访问区域。
Astroid: 从样本中学习签名(即从几个输入恶意家族 ICCG 生成公共子图)。设计并优化了定制的目标函数,该函数编码了顶点覆盖的规模和生成的公共子图的可疑性。
2.3 模型预测、评价及解释
- MAMADroid 在恶意软件分类结果上评估F度量、精确度和召回率
- Drebin 在恶意软件分类结果上评估准确度和假阳率
- HSOMINER 评估HSO预测结果的精确度和召回率
- SAD THUG 评估恶意镜像文件预测的真正例比率和真负例比率
- Feng, Q等 评估图像文件漏洞评估结果的真正例率和准确度
- DEBIN 在程序元素预测上评估准确度、精确度、召回率和F1
- Asm2vec 在相似性预测结果上评估真正例率、召回率、假正例和精确度
- EKLAVYA 评估函数信息预测的准确性
- Gemini 在相似性预测结果上评估准确度和ROC曲线
- DEEPVSA 在VSA信息预测结果上评估精确度、召回率和F1。
- Astroid 评估恶意应用程序预测的准确度和假阳率。
3. 基于软件工程的二进制代码分析
3.1 离线分析
即静态地分析。包含两个步骤,包括
- 1)预处理,将二进制代码转为IR
- 2)程序分析,广泛使用传统的静态程序分析方法(例如,代码切片、污点分析、数据流分析、布尔可满足性推理)和符号执行。还可以包括一些其他方法,例如计算特征几何中心和基于自然语言处理(NLP)的方法。
预处理
找到感兴趣的指令来对二进制代码进行预处理
Harry: 不需要转换全部指令
原始代码:
- BATE (2018): 使用模式匹配来找到与控制流防护(CFG)相关的代码(code gadget),称为PR-代码和S-代码,作为易受攻击的原始代码
- KEPLER (2019): 静态地识别五种代码段(code gadgets)作为候选的易受攻击的原始代码
反汇编或IR:
- OOAnalyzer (2018): 反汇编,将二进制代码划分为单独的函数。
- NORAX (2017): 反汇编
- ROBOROS (2015):反汇编,并用验证器检查反汇编结果
- RAMBLR (2017): 对基本块进行反汇编,并将二进制代码内容分类为代码、指针、数组等。
- TriggerScope (2016): 解包Android APK,并转成IR
- IccTA (2015): 将Dalvik字节码转换为Jimple,并提取了Inter-Component Communication (ICC) 链接以及收集的数据(例如 ICC 调用参数或 Intent Filter 值)
- MassVet (2015):反汇编为 SMALI 表示
- CoP (2014): 反汇编,并转成IR
图:
- XPMChecker (2018): 解析APK文件并构建了过程间控制流图(ICFG)
- Flowdroid (2014): 解压APK文件并解析其布局XML文件、DEX文件和清单文件。然后从生命周期和回调方法列表中生成虚拟主方法,并生成过程间控制流图(ICFG)
- IccTA (2015): 使用修改后的 FlowDroid来构建应用程序的完整控制流图。
- Arcade (2018): 识别公共入口点或API后构建CFG,然后据此生成访问控制流图(AFG)并将其转换为保护映射
- Apposcopy (2015): 执行指针分析并构造了组件间调用图(ICCG)
- Cruiser (2019): 找到具有有条件触发的UI的View Controllers(VCs)。为此,从二进制文件和其他布局文件中构建了两个带标签的视图控制器图(LVCGs)
- CoP (2014): 构建 CFG 和调用图(CG)
- Bingo (2016): 反汇编并构建 CFG
- RAMBLR (2017): 控制流图(CFG)
总结如下:
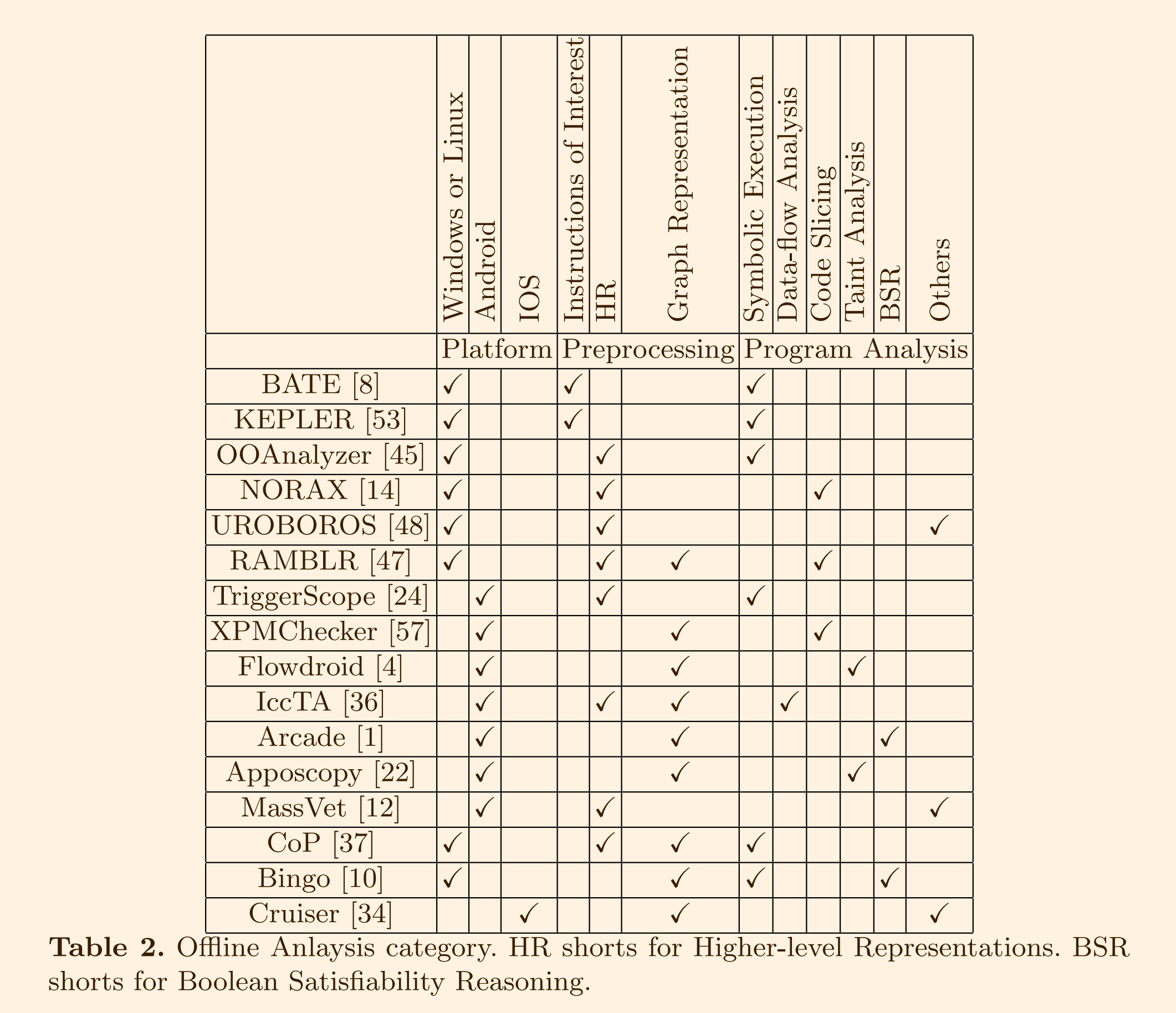
程序分析
符号执行
- BATE 和 KEPLER 使用符号执行来验证候选易受攻击的代码片段的可利用性
- OOAnalyzer 使用符号执行将低级指令行为表示为实体事实
Harry:
使用符号执行将低级指令行为表示为实体事实的一般步骤:
抽象化操作数: 在符号执行的过程中,将程序中的每个操作数抽象为一个符号,而不是具体的数值。这样,每个操作都用符号表示,而不是实际的数据。
表示低级指令行为: 针对每个执行的低级指令,记录与之相关的符号表示。这可能涉及到符号寄存器、符号内存位置等。
实体事实提取: 根据符号执行的结果,提取关键的实体事实。这可以包括对符号表示的解析,以及对程序执行路径上的关键事件的捕获。
实体事实表示: 将提取的实体事实以某种数据结构或表示形式存储,以便进一步的分析和处理。这可能包括构建抽象语法树、生成图形表示等。
通过这些步骤,符号执行可以帮助捕获程序的抽象行为,将低级指令映射为实体事实,从而支持对程序行为的深入分析和理解。
- CoP 使用符号执行来表示每个基本块的语义
- Bingo 使用符号表达式提取语义特征,捕捉部分跟踪之前和之后的关系。
- TriggerScope 使用符号执行来提取块谓词。
Harry:
在符号执行的过程中,每个基本块的执行路径都会被记录下来。块谓词是指在每个基本块执行路径上的条件表达式,这些条件表达式涉及到程序中的符号值。这些条件表达式捕获了在程序执行过程中对条件的约束
数据流分析
一些初始指令为输入,并提取所有可能传播到输入指令的指令
- IccTA: 使用精确的数据流分析来检测基于Inter-Component Communication(ICC)的隐私泄漏。
代码切片
以一些初始指令为输入,并提取二进制代码中所有与数据流或控制流相关的指令
- NORAX:使用代码切片帮助转换二进制代码
- RAMBLR: 使用程序切片执行数据识别和类型识别
- XPMChecker: 沿着ICFG进行反向切片,收集构建URL所需的所有指令。它还使用程序切片来重建与字符串相关的操作。
Harry:
通过提取与给定初始指令相关的数据流和控制流信息来简化程序的方法,代码切片的目标是根据程序的某些性质或准则,减小程序的规模,同时保留与特定问题相关的关键部分。
污点分析
获取可能引入恶意用户输入的一些不可信指令,并通过分析程序的信息流(即数据流和控制流)提取可能的汇聚指令(即从潜在的恶意用户输入中获取值的指令)。
- Flowdroid: 实施了前向和后向的污点分析。
- Apposcopy: 使用污点分析构建组件间调用图(ICCG)和数据流。
布尔可满足性推理
- Arcade:使用布尔可满足性推理来提取应用程序需要保持的最低权限
- Bingo:使用Z3约束求解器从符号表达式生成输入/输出样本,并将它们馈送到机器学习模块以找到语义上相似的函数。
Harry:
布尔可满足性(Boolean Satisfiability,简称SAT)是一种逻辑问题求解方法,通常用于判断一个给定的布尔表达式是否有满足条件的变量赋值,使得整个表达式为真。SAT问题可以描述为找到一组布尔变量的赋值,使得布尔表达式的值为真。
在SAT问题中,布尔表达式通常是一个由逻辑运算符(如AND、OR、NOT等)组成的复杂逻辑公式。解决SAT问题的目标是找到使得这个布尔表达式为真的变量赋值。如果存在这样的变量赋值,表达式被称为是“可满足的”(satisfiable),否则被称为是“不可满足的”(unsatisfiable)。
SAT问题是一个NP完全问题,这意味着在一般情况下,没有已知的高效算法可以在多项式时间内解决所有的SAT实例。
其他方法
- MassVet:计算视图图和控制流图的几何中心
- Cruiser:使用自然语言处理技术识别应用程序文本信息中的不一致性。
- UROBOROS:识别二进制代码中的符号引用并对其进行符号化。
Harry:
⭕ 没有包含抽象解释?
总结如下:
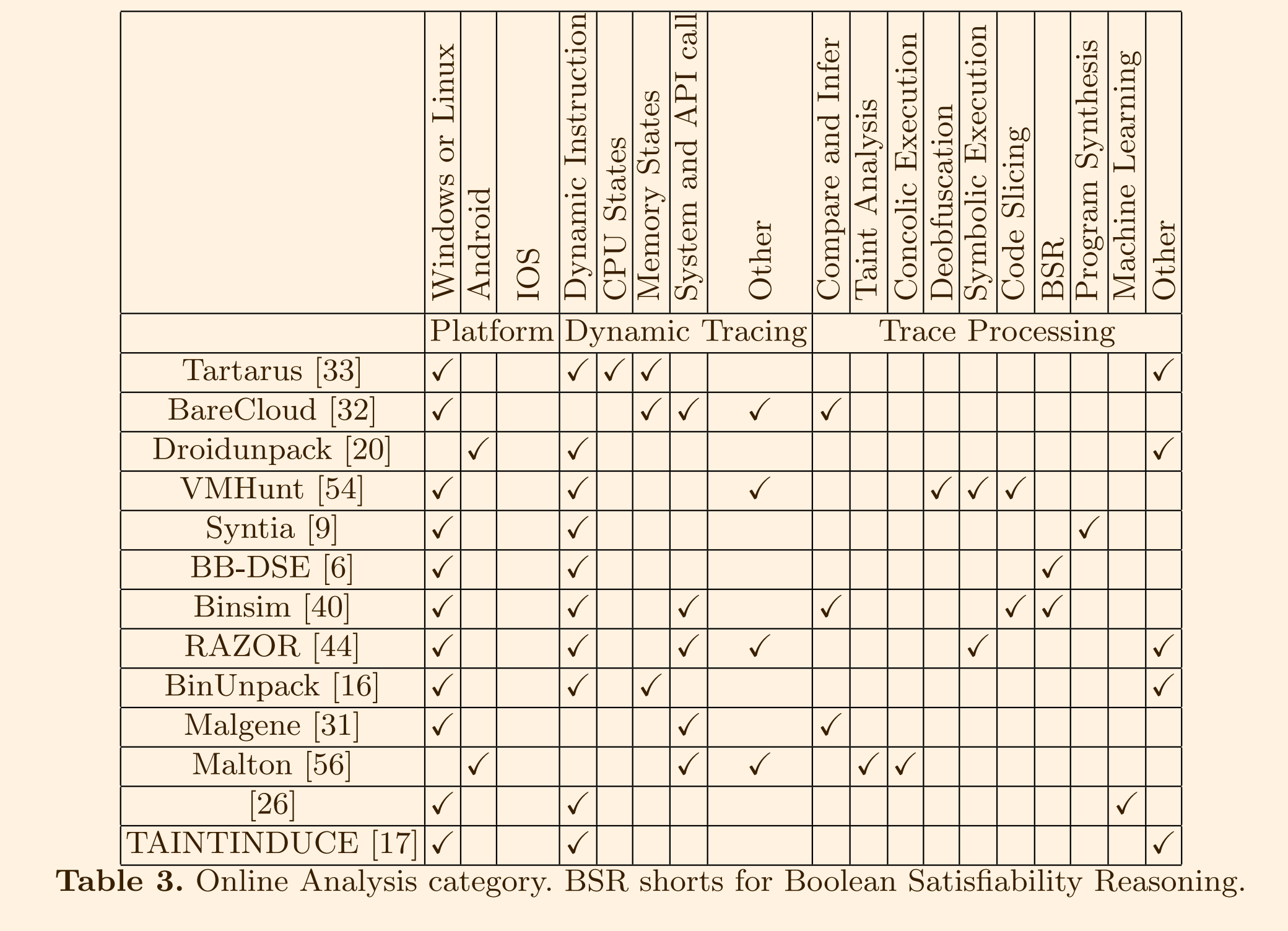
3.2 在线分析
在线分析要求程序使用具体的输入进行执行。在执行过程中,会跟踪运行时信息(例如内存或CPU状态、执行的指令、系统和API调用等)。然后基于跟踪的信息进行各种分析(例如传统的程序分析方法、机器学习、程序合成等)。
动态跟踪
- Tartarus(2017): 使用影子内存来记录恶意软件的执行轨迹,包括内存和 CPU 状态。
- BareCloud(2014): 追踪一些预先计算的内存地址的执行,记录 Windows API 调用和系统调用。
- Droidunpack(2018): 在 Linux 和 DVM 上追踪指令,支持使用挂钩技术追踪 Android Runtime (ART)。
- VMHunt(2018): 动态运行虚拟化二进制文件并记录跟踪,包括指令的内存地址、指令名称、源和目标操作数、运行时信息等。
- Syntia(2017): 追踪动态执行的指令。
- BB-DSE (Backward Bounded Dynamic Symbolic Execution)(2017): 追踪动态执行的指令。
- Binsim(2017): 记录执行的指令及其操作码和操作数,还记录内存访问地址。
- RAZOR(2019): 追踪执行的指令及其内存地址和原始字节。
- M Ghaffarinia etc.(2019): 生成执行轨迹。
- TAINTINDUCE(2019): 记录动态执行轨迹,具体包括每条指令执行前后的内存地址和完整的寄存器状态。
- BinUnpack(2018): 使用内核级 DLL 劫持技术追踪恶意软件的动态执行指令,该技术通过将标准 DLL 装载中的 DLL 替换为带有嵌入的监视功能的新版本。
其他跟踪对象:
- 系统和 API 调用: Windows API 调用、系统调用、网络流量、用户环境数据(例如浏览器历史记录、用户文档文件等)、磁盘级状态变化等
跟踪分析
- BareCloud: 通过比较追踪的恶意软件日志和正常程序日志,提取恶意软件行为。
- Malgene(2015): 应用从生物信息学中借鉴的序列比对算法,对系统调用序列进行比对,找到逃避行为并提取逃避特征。
- Binsim(2017): 使用从 MalGene借鉴的系统调用对齐方法匹配追踪结果,检查二进制代码的相似性。
典型的技术包括代码切片、污点分析、符号执行、共轭执行等。
- Malton: 通过污点分析、路径探索技术和共轭执行来表征恶意软件行为。
- VMHunt: 通过使用反向切片算法和多层次符号执行来定位虚拟化代码并去混淆虚拟化代码。
- Binsim: 进行动态切片来检查相似性
- RAZOR: 使用基本块符号化来提取去除冗余代码。
Harry:
共轭执行(Concolic Execution)是一种混合符号执行和具体执行的程序分析技术。在共轭执行中,程序以两种方式执行:符号执行和具体执行。符号执行使用符号值(代表未知具体值的符号)来代替程序中的变量,从而创建关于程序路径的符号表达式。具体执行则使用实际输入值来执行程序路径。这两种执行方式相结合,形成了"共轭"的执行方式。
在共轭执行中,符号执行生成的符号表达式用于表示程序的约束条件,这些约束条件由具体执行提供的输入值实例化。这种混合执行的好处在于,符号执行允许对程序的多个路径进行符号化分析,而具体执行通过实际输入值的执行来验证符号化路径的可行性。
在程序的某个点上使用布尔可满足性(或 SAT)推理可以帮助检查分支的可达性,并用于比较相似性。
- Backward-Bounded Dynamic Symbolic Execution (BB-DSE):推理执行流是否不能达到某个指令地址。这是通过向程序中某个点后向推理,使用 SMT 求解器来决定所有前驱条件是否满足。
- Binsim: 使用最弱前提(一种布尔公式)来检查相似性。
从追踪中合成程序可以帮助简化程序的语义信息,从而去混淆程序
- Syntia: 随机生成输入和输出对作为追踪窗口的语义,使用蒙特卡罗树搜索方法合成程序。
机器学习也可以用于分析追踪结果
- Ghaffarinia M etc. 使用基于机器学习的方法学习开发人员预期但用户不希望的代码
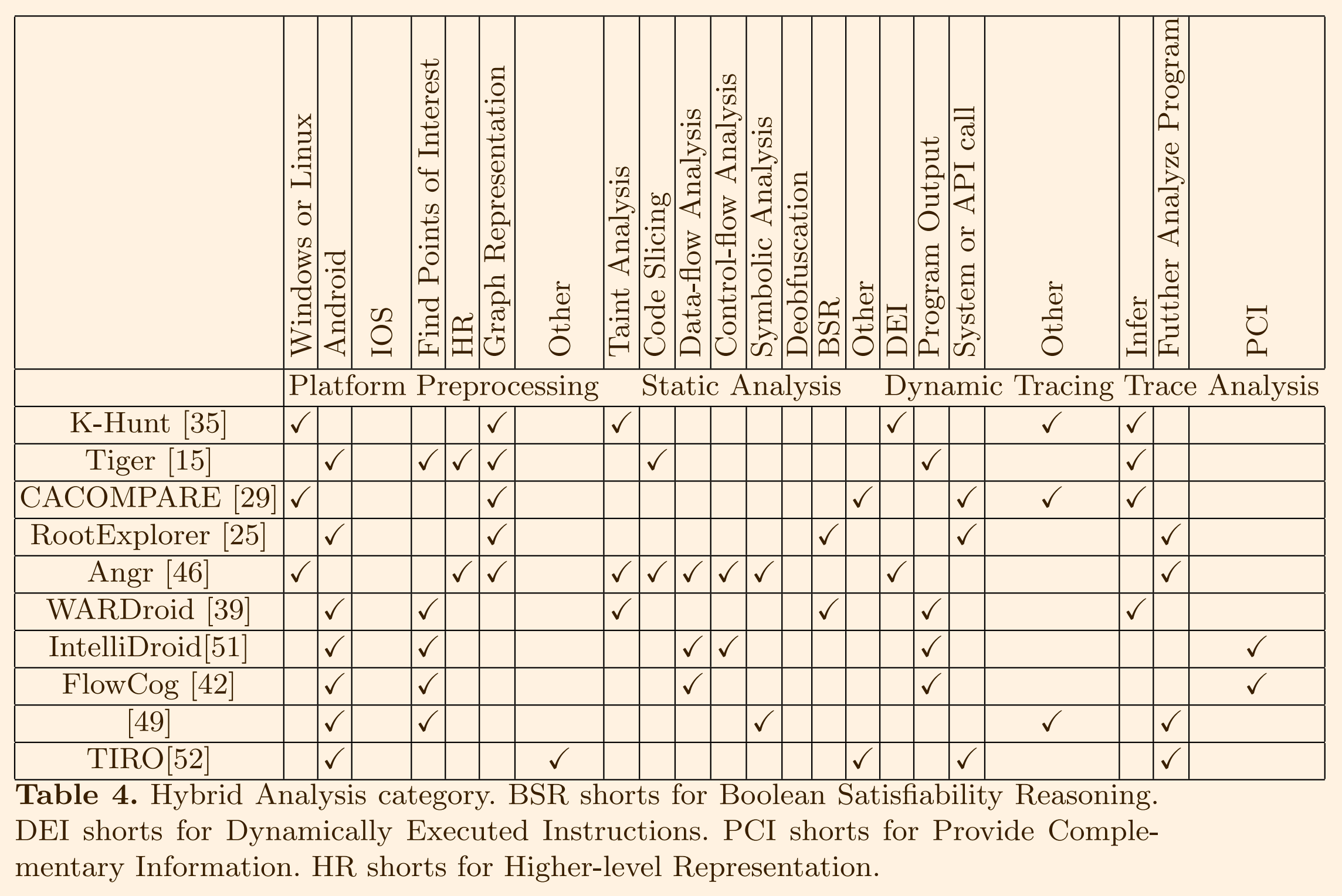
3.3 混合分析
它包括四个步骤:
- 预处理,将二进制代码抽象为高级表示或基于图的表示,或提取感兴趣的初始点。
- 静态分析,使用传统的静态和符号分析。
- 动态跟踪,使用具体值执行程序并跟踪运行时信息。
- 跟踪分析,执行各种分析。
预处理
- K-Hunt(2018): 对二进制代码进行反汇编并恢复控制流程图(CFG)以生成基本块
- Tiger(2017): 构建应用程序的调用图(CG),将应用的DEX字节码反汇编为SMALI中间表示(IR),定位应用的所有网络接口点(即,发送消息的API)
- CACOMPARE(2017):通过反汇编和生成CFG对二进制进行预处理
- RootExplorer(2017): 使用IDA Pro对二进制代码进行反汇编并恢复CFG
- Angr:可以将二进制代码转换为CFG,是一个二进制分析框架,支持使用libVEX和PyVEX从多种架构转换为中间表示
- WARDroid(2018): 通过扩展FlowDoroid在APK中识别兴趣点(POIs)
- IntelliDroid(2016): 通过抽象API调用首先识别目标API调用
- FlowCog(2018):通过使用一组数据流分析将Android视图与数据流或数据流的激活事件和保护条件相关联
- Wang X. etc.: 首先识别消息处理函数
静态分析
传统的程序分析技术
- WARDroid: 使用向后污点传播跟踪与Web API相关的数据流。然后,通过构建调用图、指针分析、定义-使用链分析和污点分析重建应用程序的程序依赖图(PDG)
- Tiger: 执行后向切片以查找通过该接口发送的语句
- IntelliDroid:通过使用前向控制和数据流分析提取调用路径约束
- FlowCog: 通过使用一组数据流分析将Android视图与数据流或数据流的激活事件和保护条件相关联
- Angr: 支持静态漏洞发现(例如,恢复控制流、使用数据建模的漏洞检测以及使用流建模的漏洞检测)
- Wang X. etc: 使用符号分析推断具有符号约束的响应消息
- K-Hunt(2018): 使用污点分析检测弱加密实现
布尔可满足性(或SAT)推理:
- WARDroid:还构建了一个Z3兼容公式(即布尔公式)和正则表达式的模板。它通过解决布尔公式生成潜在的易受攻击的输入和请求。
- RootExplorer: 通过符号执行解决了需要满足的前提条件,以识别成功执行根利用的可行执行路径。
其他分析技术
- K-Hunt: 计算每个块的x86/64算术和位操作指令(例如,mul、xor等)的比率,如果比率达到某个阈值,则将该块视为候选的加密基本块
- TIRO(2018): 检测潜在的混淆位置,并使用IntelliDroid解混淆代码
- CACOMPARE: 遍历CFG以识别执行所需的参数,通过观察它们在堆栈上的行为。它还检测包含间接跳转的所有可能目标地址的开关语句
动态追踪
记录指令和使用的缓冲区
- K-Hunt:使用Intel PIN追踪动态执行的指令和与密钥生成和传播相关的缓冲区
- Angr: 支持动态执行追踪。
记录程序输出
- WARDroid: 将伪造的有效和无效的HTTP请求发送到服务器并获取响应
- IntelliDroid: 动态提取在运行时满足约束的具体值
- FlowCog: 可输出特定字符串和视图ID
- Tiger: 使用Dalvik虚拟机(VM)上的部分执行来记录输出流量标记
系统调用或API调用
- TIRO: 追踪调用者方法、调用站点和实际执行的方法
- CACOMPARE: 追踪库函数调用
- RootExplorer: 追踪系统调用
追踪其他动态信息
- K-Hunt:追踪执行统计信息(例如,基本块的执行次数、数据包的随机性)。
- CACOMPARE: 使用随机生成的输入来模拟执行。收集的语义签名包括函数输入和输出值、比较操作数和条件代码。
- Wang X. etc: 记录执行堆栈。
追踪分析
使用动态跟踪来推断信息
- K-Hunt: 使用不同大小幅度的输入测试基本块的数据敏感性,还使用卡方分布和蒙特卡洛π近似测试来测量收集的数据包的随机性。
- WARDroid: 使用编辑距离算法来推断服务器是否接受无效的请求
- Tiger: 比较输入和输出流量标记,以测试每个输入对输出不变部分的影响
- CACOMPARE: 使用输入和输出关系作为签名,计算两个签名序列之间的相似性。
使用追踪信息分析程序
- TIRO:利用观察到的信息(例如,执行的调用者方法、调用站点和实际执行的方法)构建静态调用图并去混淆混淆的代码。
- Angr:支持动态漏洞发现(例如,动态具体执行)和利用(例如,崩溃复现、利用生成、利用强化)
- RootExplorer:使用追踪的系统调用形成行为图
- Wang X. etc.: 使用追踪的堆栈执行信息将应用程序的请求和响应配对。
将动态跟踪视为获取静态难以获取信息的补充方法
- IntelliDroid: 将记录的运行时具体值应用于伪造导致调用目标API的输入
- FlowCog: 使用动态解析的字符串和视图ID来辅助语义提取。
总结如下:
4. 挑战与展望
4.1 二进制优化与混淆
二进制优化(例如,整个程序优化、链接器重用相同函数实现以及函数内联可以使二进制代码变得非常复杂)对于自动二进制分析提出了挑战
二进制混淆也使二进制代码变得复杂且难以分析
一个可能的对策是探索应用程序和运行时内存的分离
4.2 对抗二级制分析
针对二进制分析的典型对抗性机器学习包括毒化攻击、特洛伊木马和后门攻击、重编程攻击、推理攻击和逃避攻击。
- 毒化攻击可以向训练集注入精心制作的二进制样本,以降低机器学习方法的性能。在蠕虫签名生成、DoS攻击检测和PDF恶意软件分类等方面,毒化攻击已经证明了其有效性
- 特洛伊木马和后门攻击的目标是在常规输入下保持模型的行为,同时在特定触发条件下表现出不良行为
- 重编程攻击的目标是重新编程模型以执行攻击者选择的任务,而不是执行原始任务
- 逃避攻击发生在将看似属于一类的对抗性示例输入到模型中,人类认为它属于另一类,但模型对其进行分类为另一类
4.3 先进的动态攻击
先进的动态攻击可以逃避静态和动态二进制分析。
- 二进制分析技术无法处理反射、动态代码加载或本机代码等攻击。
- 对于动态分析来说,未执行的代码仍然是一个挑战。
- 存在一些高级的反动态分析技术来阻止动态分析。例如,通过监视鼠标光标的移动可以逃避动态分析、在运行时生成或自修改代码绕过当前的动态二进制分析
- 在编程中的动态链接也是二进制分析的一个未解决的问题